Machine Learning Peril Wizard
Redesigned peril determination with a new UI and NLP/ML model to reduce mis-triaging, lower customer effort, and improve claim initiation quality on web.
Problem
Business value: 10% of claims were refiled, and 65% of those refiles were caused by users mis-triaging peril. Customer value: the existing peril experience was too long, too complex, and difficult to scan on mobile.
Proposed Solution
Through a redesigned UI and peril determination ML model, we tested a simpler, more accurate path for peril selection with a confidence-based fallback to current experience.
Primary metrics
Refile rate and initiations as top-line indicators.
Granular metrics
Repair/replace rates, model edit frequency, prediction coverage.
Experience quality
CLOE and time-to-complete to validate that the flow actually feels easier.
How
Peril Wizard uses NLP and ML trained on 50K historical Sprint customer text descriptions to predict peril types (single and combined keywords). We only accept prediction when confidence clears a strict threshold; otherwise users continue through fallback.
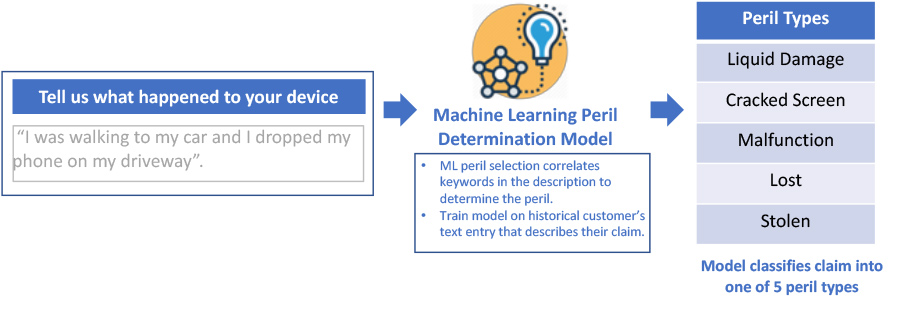
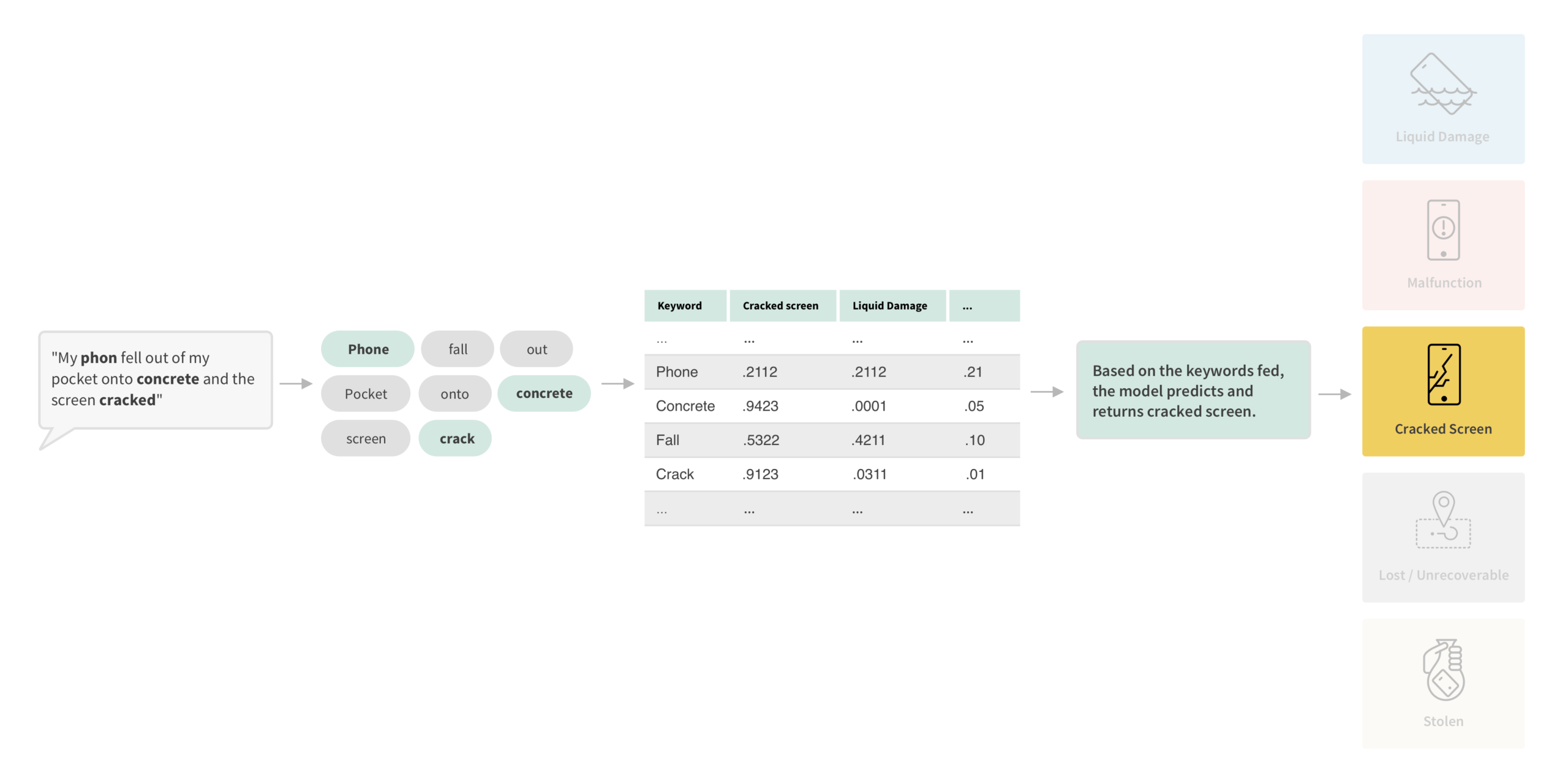
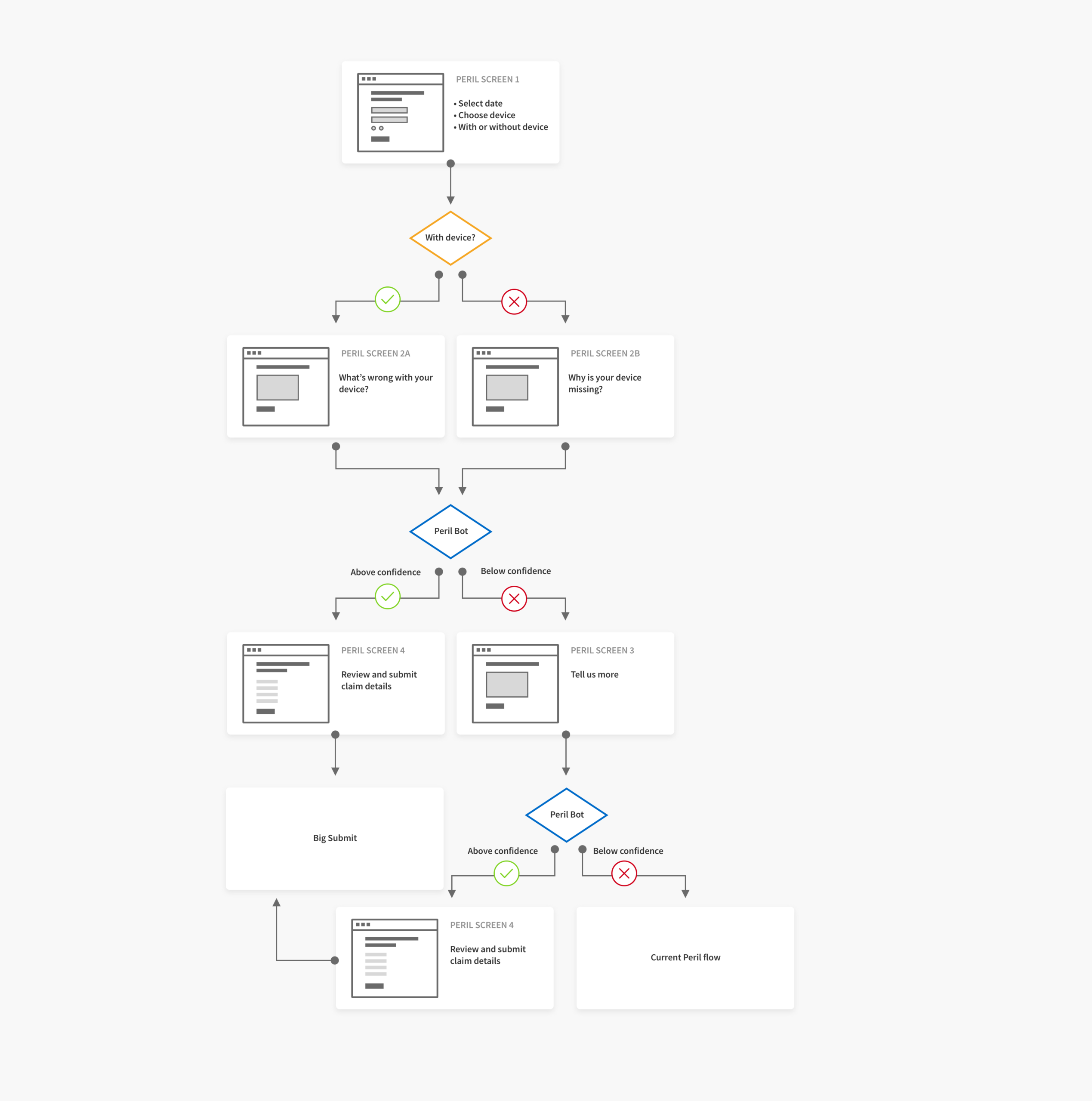
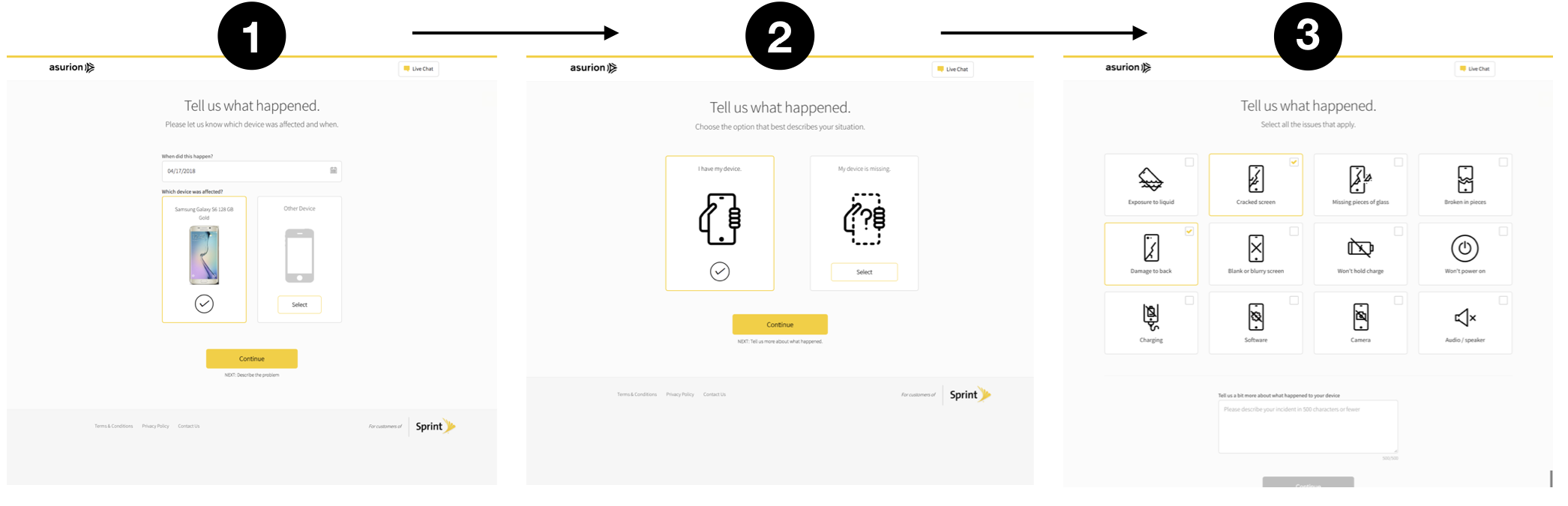
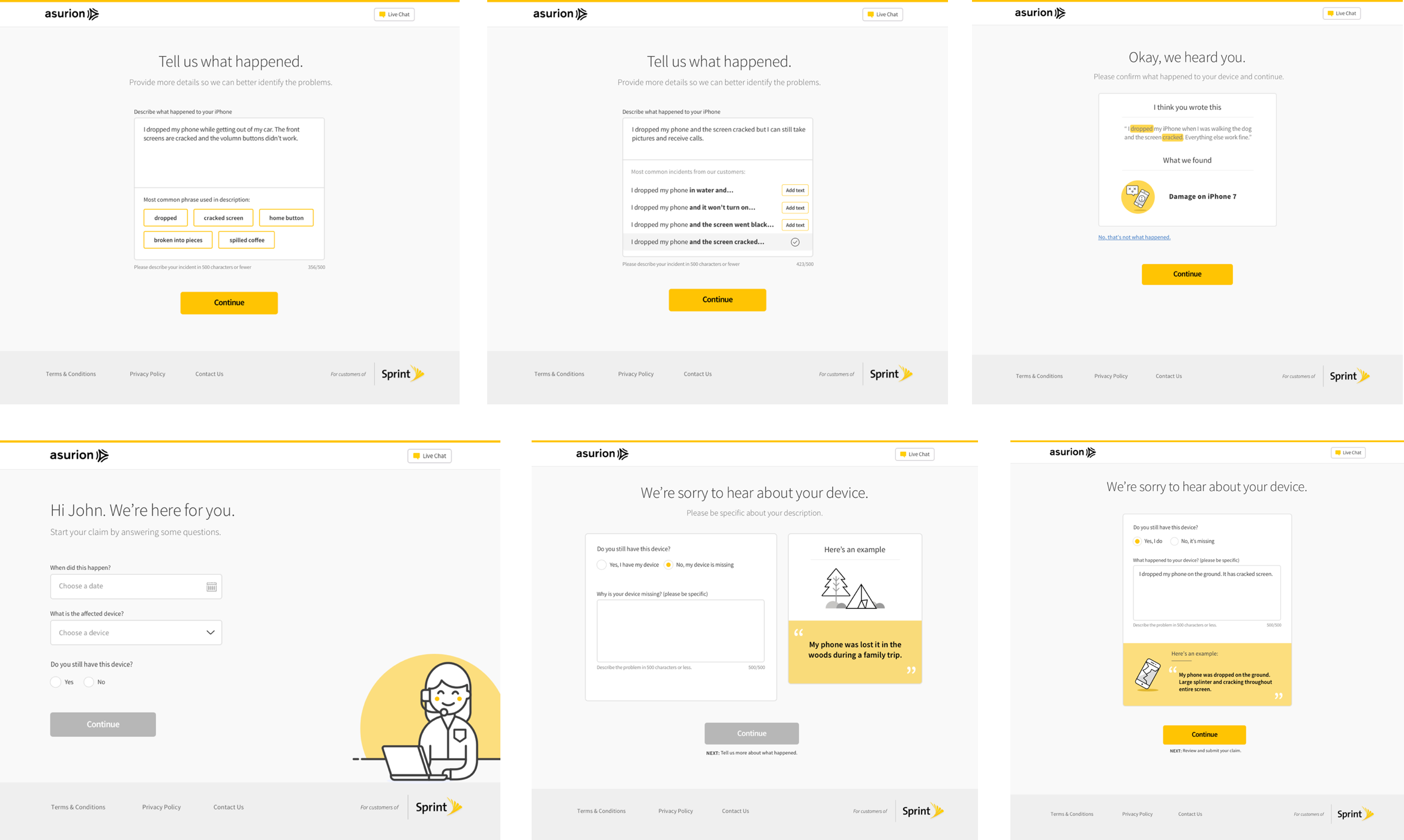
UI Iterations
We iterated through concept and step-by-step flows while balancing model behavior with trust and readability in the new interface.

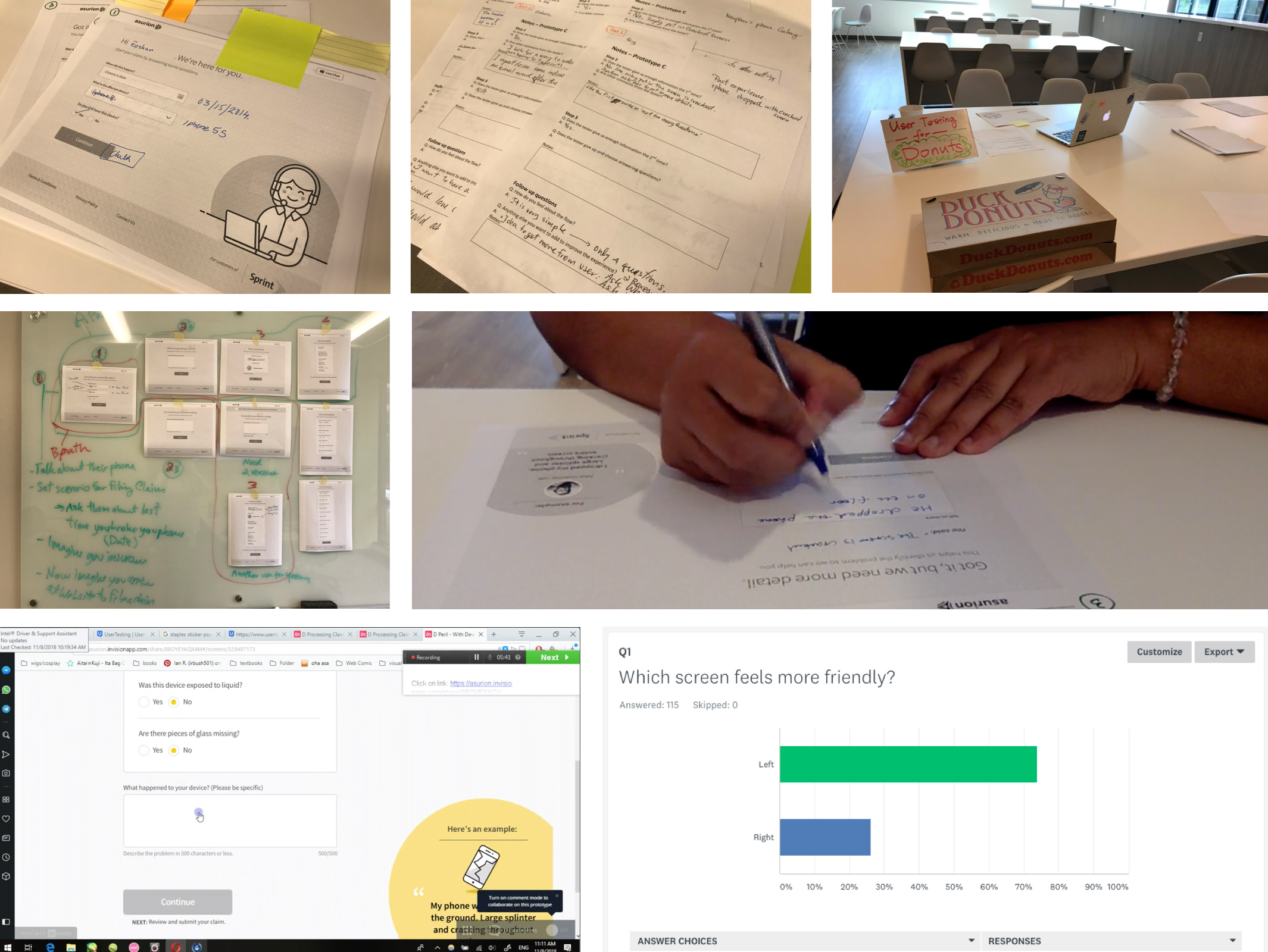
User Testings
We ran in-person paper prototype tests, SurveyMonkey impression tests, and end-to-end validation to assess comfort with text entry and confidence in model-guided peril selection.
Paper Prototype UT:
Dropbox Paper
SurveyMonkey Impression Test:
Dropbox Paper
Result
We launched at 25% traffic for two weeks, then planned ramp-up to 50% and 100% as leading metrics stayed favorable after iterative model/UI tuning.
- CLOE dropped from about 230s (control) to about 188s (pilot), ~45s reduction.
- Web NPS showed no negative impact, with slight positive movement.
- Web initiations rose by about 1.3% while completion rates remained comparable.
- Repair rates stayed at parity overall with slight completion uplift.
- Prediction-rate monitoring validated model usefulness and fallback behavior.